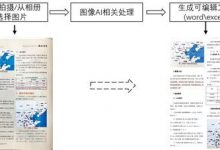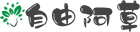
导语:ABC时代(AI+BigData+Cloud),作为腾讯云大数据及人工智能产品中心的一员,也算是站在了toB+ABC的“腾讯风口“。分享一些在AI领域作为一名商业产品经理的心得,希望尽可能系统化。适合对AI感兴趣的人群,无需产品和算法/研发背景知识。
前言
明镜所以照形,古事所以知今。无论做哪个行业属于哪个领域,我们回顾历史,总是可以发现一些规律,一些似曾相识。回顾历史,我们可以总结历史经验、把握历史规律,增强开拓前进的勇气和力量。
AI发展的三大浪潮
事物发展总是有周期的,大到一个国家/朝代的发展变更,小到一个月总有那么三十几天不想上班。AI也是一样。作为一个从上世纪50年代才发展起的技术/学科,一般大家讲AI的发展历史,总是会总结成三大浪潮。幸运的是,目前看起来,AI还是总体符合波浪式前进、螺旋式上升的趋势,值得广大有志青年来投身于此。
[ 波浪式前进、螺旋式上升的人工智能 ]
三次浪潮的定义并没有一个官方标准,此处的定义采用了日本学者松尾丰的定义。
第一次浪潮——搜索与推理(约上世纪50-70年代)
图灵测试
AI的发展简史,要从盘古开天辟地说起。1950年,阿兰·图灵(Alan Turing,一位科学巨匠,感兴趣的同学可以看下《模仿游戏》这部电影),在《mind》上发表了一篇名为《计算机器和智能》(Computing Machinery and Intelligence)的论文。论文中既没讲计算机如何变得智能,也没提出什么解决复杂问题的智能方法,仅仅是提出了一种验证机器有无智能的判别方法:让测试者和计算机通过键盘和屏幕进行交流,测试者事前并不知道与之对话的到底是机器还是人类。如果测试者无法分辨自己交流的对象是人还是机器,那么我们就说这台机器通过了测试并具备了人工智能。
这个测试非常有趣,还有一个专门的奖项(Loebner Prize),用来颁发给那些在测试中表现优异的程序。有些人还会长期霸榜。
下图的代码截图,是“AI核心代码,估值一个亿”。这段代码只做了一件事情,就是将输入文字进行非常简单的处理——将输入的“吗”字去掉,将输入的问号“?”替换成感叹号“!”。尽管是讽刺某些AI领域的欺诈现象,但我相信的确可以通过某些人的图灵测试。
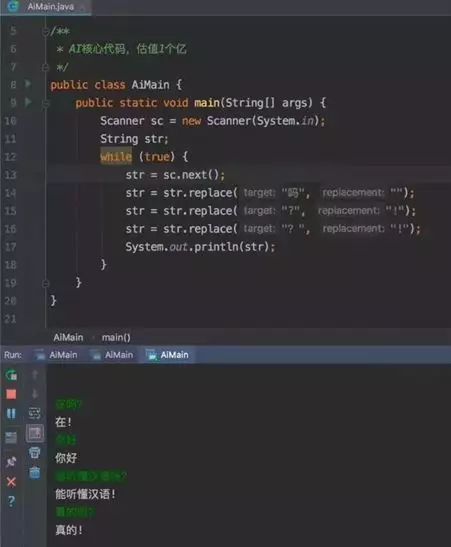
[ 估值1个亿的AI核心代码 ]
达特茅斯会议
1956年夏天,香农和一群年轻的学者在达特茅斯学院召开了一次头脑风暴式的研讨会。会议的倡议者是当时在该学院任教的John McCarthy和Marvin Minsky,他们当时都只有29岁(29岁!)。说是研讨会,但和现在的为期几天的学术会议不一样,这个研讨会持续了一个暑假。“人工智能”这个概念,就是在这次会议上提出的。
搜索与推理
我们先看一个迷宫问题。假如有下图最上方的一个迷宫,我们如何从起点走向终点?如果是人类,我们一般会拿笔画勾勒路线,或者通过语言描述。但是计算机无法这样处理,我们要将问题表示成下图中间的样子,路径由线段表示,节点由字母表示,起点我们标记为“S-Start”,终点我们标记为“G-Goal”。
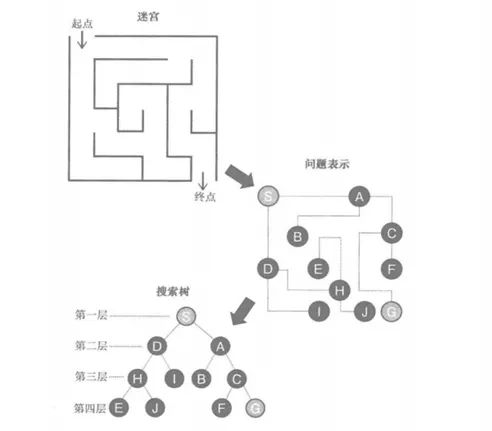
[ 将迷宫问题表达给计算机理解 ]
从S开始出发,我们会有A、D两个方向可以选择,从A出发我们有B、C两个方向,从D出发我们有H、I两个方向,以此类推,我们可以将所有可能出现的路径表达成上图最下方的树状结构。
那么,现在问题就表示成,我们有上图所示的搜索树,如何让计算机找到从S到G的路径?
简单的方法有两种:
1,我们尽量往深挖,走到不能走了为止,不行了就换一个树的分支,这种方法被称为“深度优先搜索”;
2,我们尽量把同一层级的节点都试过后,发现没找到G,再进入到下一个层级,这种方法被称为“宽度优先搜索”。两种方法各有利弊,也能根据这两种方法延伸出很多复杂的搜索算法。
最终我们发现,如果要从S->G,路径是S->A->C->G。
P.S.:
1. 所谓算法,是指解决问题的方法和步骤。冒泡排序也是一种算法,并非AI相关的算法才是算法。
2. 没有coding基础的同学也建议看看最基础的数据结构和排序算法。
成就和问题
盘古时代的AI,让人们看到了以后不用工作靠机器人养活的曙光,尤其是在解决智力游戏问题上让人们惊叹不已。期间最有代表性的是棋类游戏。
1997年,由IBM开发的超级计算机“深蓝”打败了当时国际象棋的世界冠军Garry Kasparov,引发的轰动不亚于Alpha Go击败李世石。虽然这件事情时间线上不属于AI的第一次浪潮,但“深蓝”当时使用的方法,本质还是暴力搜索——通过对己方或对方的每个可能的棋步进行搜索,然后选出获胜概率最大的棋步(不过据说深蓝根据Garry Kasparov的棋路做了专门优化,连硬件都是定制的)。

[ 深蓝战胜Kasparov ]
这个时期能解决的问题其实非常有限,现实生活中一些没有明确规则的问题难以解决,同时机器的算力也非常有限。人们最终认为AI只能解决一些“Toy Problem”。
第二次浪潮——专家系统(约上世纪80-90年代)
既定规则
1966年,MIT的教授Joseph Weizenbaum发明了一个对话小程序ELIZA,这个对话小程序可以通过谈话帮助病人完成心理恢复。ELIZA是微软小冰、小黄鸭、Siri这些对话机器人的鼻祖。ELIZA的原理非常简单,在一个有限的话题库里,用关键字映射的方式,根据病人的问话,找到自己的回答。比如,当用户说“你好”时,ELIZA就说:“我很好。跟我说说你的情况。”此外,ELIZA会用“为什么?”“请详细解释一下”之类引导性的句子,来让整个对话不停地持续下去。同时,ELIZA还有一个非常聪明的技巧,它可以通过人称和句式替换来重复用户的句子,例如用户说“我感到孤独和难过”,ELIZA会说“为什么你感到孤独和难过”。
P.S.:感觉Joseph是一个很好的C端产品经理。
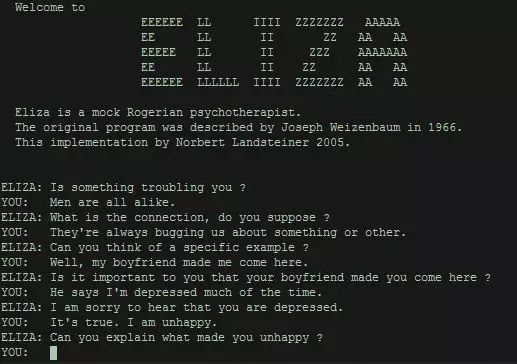
[ ELIZA对话 ]
专家系统
专家系统,顾名思义,就是通过引入某个领域的专业知识,利用事先预定规则(可以简单理解为很多个If-else),机器就可以像专家一样出色地工作。有个很有名的专家系统是上世纪70年代初由斯坦福大学开发的MYCIN。MYCIN的功能设计是对传染性血液病患者进行诊断,并开出抗生素药方。这个系统内部总共有500条规则,只要按照既定顺序依次回答,那么系统就可以判断病人所感染细菌的类别,并开出药方。
从效果上来看,MYCIN开出正确处方的概率为69%,其成绩优于非细菌感染专业的医生,但低于专业医生(正确率为80%)。就效果而言,50年前能达到如此效果,已是殊为不易。
一个很著名的项目——Cyc计划,旨在打包人类所有知识,从1984年开始,至今仍未结束。
[ 知识 ]

[ Cyc的官网介绍 ]
成就和问题
专家系统在数据不精确或信息不完整、人类专家短缺或专门知识十分昂贵的场景下,取得了非常好的效果和经济收益。专家系统的一个著名例子,是IBM开发的人工智能“沃森”曾参加美国电视智力问答节目“危机边缘”并挑战历代冠军而获胜。而且,据称在上世纪80年代已有约2/3的美国1000强企业在日常业务中使用了专家系统。
但是很明显的,专家系统有很多问题。知识库的建立需要大量的时间、人力、物力;有些模糊无法定量的问题难以用文字衡量(类似我肚子痛,请问有多痛?);知识/信息是无限的;机器翻译始终无法取得预期效果(AI翻译是个很有趣的话题)。
第三次浪潮——机器学习、深度学习、计算机视觉
鸟飞派 VS. 统计派
按照吴军博士的说法,AI领域一直存在着鸟飞派和统计派两派。鸟飞派认为,要首先了解人类是如何产生智能的,然后让计算机按照人的思路去做。这个说法来自于古人希望飞翔,于是通过观察鸟类是如何飞行的,通过模仿鸟类来达到飞翔的目的。当然我们现在知道插满羽毛的“鸟人”是飞不起来的。怀特兄弟发明飞机是靠空气动力学而不是仿生学。现在,一般我们现在用的机器翻译和语音识别,都是靠的数学,更准确地说是统计学。
机器学习,则属于统计派。
机器学习
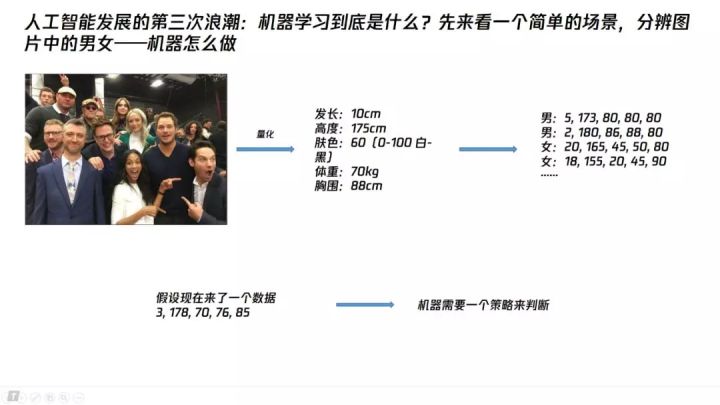
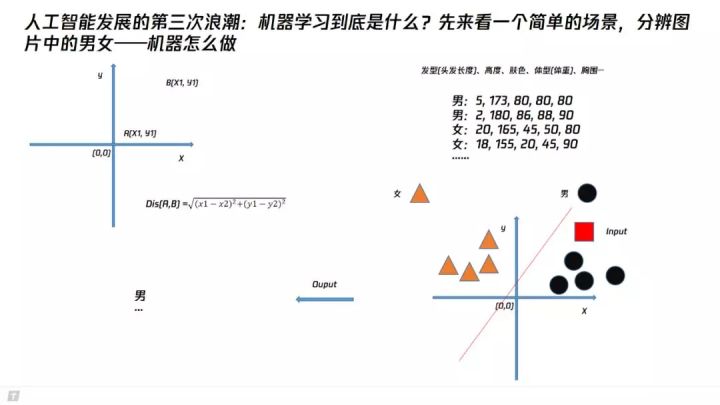
聊机器学习前,我们先看一个简单的问题。下图中明星合照,如果要分辨图片中的男女,人类会怎么做?
其实人类可能一眼看过去就分辨出来了,当然我们人类分辨图片中的男女可能隐含着我们使用了图片中人物的发型、高度、肤色、体型等等信息,再加上我们在日常生活中积累的知识,从而做出了判断。

[ 人类分辨男女怎么做 ]
那么,同样类似我们在处理迷宫问题时的做法,我们先将这些信息给量化,方便计算机理解。我们简化这些信息,将发型用头发长度来衡量,肤色用0-100的数字衡量,体型用体重来衡量,高度和体重则保持正常大家的理解。
那么,一个发长10cm、高度175cm、肤色60、体重70kg、胸围88cm的人,可以用一串有顺序关系的数字来表达(10,175,60,70,88),这串有顺序关系的数字,在数学领域,叫做向量。在机器学习领域,我们常称其为特征向量。将图片中人物表达成特征向量的过程,我们常称为特征提取。这个特征,因为由5个有顺序关系的数字构成,我们常说这个特征是5维的。
好了,我们现在已经知道如何把一个人用特征向量来表达了。那么,在这个向量空间(这些特征所在的空间,可以把向量空间简单理解N维坐标系)中,我们怎么做,能够让机器正确分辨未知性别的人呢?我们需要给机器一个策略,让机器可以“聪明”地作出正确的判断,并且可以“学习”。
[ 机器分辨男女怎么做1 ]
我们先使用一种简单的策略——已知的向量空间中,我们有事先已知性别的某几个或一些人,我们提取这些人的特征。然后,我们设定,如果,待判断性别的人的特征向量离已知性别的人的特征向量最“近”,那么我们认为这两人的性别一样。我们可以简单理解为这种策略背后的哲学思想是“物以类聚、人以群分”。这个分类的策略在机器学习领域被称为最近邻(NN,Nearest Neighbor)。
那,怎样算“近”呢?
首先我们看下图中左上角的二维坐标空间,我们可以看到点A(X1,Y1)和点B(X2,Y2),两个点的欧式距离我们可以通过图中Dis(A,B)公式得出(此处蕴含初中数学知识)。我们可以以在特征向量空间中的欧式距离来判断“远近”。当然,实际上还有其他N种算距离的方法,如曼哈顿距离、马氏距离。
上述过程,我们就完成了一个非常简单的算法模型。我们设计了一个特征(或特征提取方法),我们有一些标注数据(事先已知性别的人),我们使用NN分类器用于进行分类。
毋庸置疑,上述模型是简陋的。会有很多问题。我们设计的特征是否足够合理呢?(体重用来判断性别合适么,小孩和老人的情况怎么办呢)我们的标注数据是否足够多且合理呢?(如果标注数据中已知性别的人中女性都是成年人,而男性都是小孩,这个时候若输入是一个成年男性的数据,是不是输出就大概率是女性了)我们的分类器是否对噪声鲁棒?(如果已知性别的人中某个女性在发长、高度、肤色、体重、胸围比较man,或者由于人工失误将数据标注错了,而恰好我们的某个男性在这些生理特征上和其相似,则容易误判)。
[ 机器分辨男女怎么做2 ]
因此,我们要改进。
- 如果,我们在特征中,加入“是否有喉结”这个因素,并根据有/无喉结表示为0和1,那么我们可以把这个特征变得更有意义,此时特征已为6维。这个过程,我们可以简单称其为“算法升级”。升级后的算法,其特征和原先的特征是不兼容的(维数都不一样了,距离无法计算)。所以绝大部分时候,AI算法升级后,原来系统存储的特征是无法被升级后的系统使用的。
- 如果考虑年龄、人种、地域分布、健康情况等多种因素,尽可能搜集多数据并确保数据标注的正确性,我们是可以提升这个系统的效果的。所以,大数据的出现对AI的推动作用是非常大的。大数据是另外一个很相关的领域,目前机器学习甚至可以被理解为大数据的一种应用。
- 如果,我们不仅仅只考虑最“近”的那一个人,而是考虑最“近”的k个人,并采用“少数服从多数”的原则来进行投票,判断性别,我们可以降低因为部分人 太Man or 太娘 带来的噪声影响。那么这个k取多少呢?3、5、7还是9?我们可以再额外采集一部分数据来测试(之前的标注数据我们称为训练数据,这次额外采集的称为测试数据),验证一下k取多少能获取最好的效果。那么这个获取最佳k的过程,我们可以称机器在学习/训练(Machine Learning/Training)。这个分类器就叫k-NN分类器。
- 如果,我们认为最近邻的思想太过简单,我们还可以来点复杂的内容。在上图中,我们可以在向量空间中划出一条线/一个平面,来进行区分。线/面的一边代表一类。这个策略(分类器),叫支持向量机(SVM)。通过标注数据找到这条线/这个平面(这个过程有大量参数待定),也是一个机器学习的过程。
- 其他常见的分类器还有贝叶斯、决策树、人工神经网络等。人工神经网络之后就发展出了深度神经网络以及后续的Deep Learning。
上面的这么一个过程,我们建立了一个判断性别的算法模型。我们学会了设计特征、设计分类器。为了达到判断性别这个目的,我们需要事先有一些数据(样本集/标注集),我们需要有一些知识才能设计出好的特征,我们的分类器需要数据来“学习“获得一组最佳参数。我们知道了,什么叫“机器学习”。
深度学习
我们在看上述辨别性别问题的时候,会发现有一个关键点——上述设计的特征是否合理?如果使用“是否有喉结”这个作为特征或甚至采用“是否有子宫”这个作为特征是否更加合理?发长、高度、肤色、体重、胸围这些因素是有助于判断性别还是无助甚至有害的?
在深度学习出现之前,学术界许多学者都在致力寻找更好的特征来表述某些事物。许多学者投入了大量时间出产大量论文只是解决某个既定领域的一个小问题,提升几个百分点的准确率。如果特征都要依赖人类来设定,甚至是专家来设定,我们能否让机器自己来设计特征?
深度学习(Deep Learning)就是解决这个问题——让机器来设计特征。

[ 深度学习是什么?]
深度学习,受自然神经网络结构启发,但并不是模拟神经网络(不是鸟飞派),其早已是数学的领域。深度学习英文名为Deep Learning,原因是其是由多层神经网络组成,理论上还是属于机器学习的范畴。(此处感慨一下,取名非常重要,转基因的作者如果取个好名字就不会有这么多事)
关于深度学习的原理,限于篇幅和笔者能力,不在此展开。有兴趣的同学请自行搜索相关内容。
计算机视觉
机器学习严格意义上可以算作一门学科,而计算机视觉(Computer Vision)实际上是图像处理和机器学习的交叉学科。
我们在上述看机器学习的过程中,有个关键步骤是提取特征。在分类男女的任务中,我们使用了诸如发长、体重此类的特征。如果我们真的要使用这些信息作为特征,那么我们会需要在现实世界中进行量取,这个可能是不一定做得到的,依赖于我们获取数据的方式。
在现在的计算机屏幕上,我们人类可以看到色彩鲜明的图片,是因为电脑屏幕通过电流刺激给人眼反射了不同波长的光,人眼的感光器对不同波长的有不同的反应,因此造成了颜色这个感受。
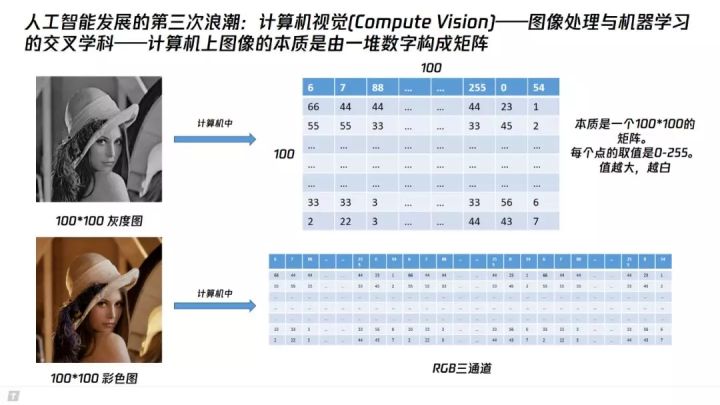
根据杨一赫姆霍尔兹学说,或叫三色学说,自然界中存在的各种颜色都可以通过红(Red)、绿(Green)、蓝(Blue)三种颜色按照不同比例混合而成。而我们现在看到的计算机上图像的本质,就是由分别代表RBG三通道的三个二维矩阵构成。
我们首先看下图中灰色的Lena(Lena是图像处理领域常用的一张美女图片。这个图片很有历史,有兴趣的同学可以搜一下)。一般我们称只有亮度(没有颜色)的图成为灰度图。一个像素为100×100的灰度图,在计算机中,就是一个100×100的二位矩阵,矩阵中的每一个值,代表每一个像素点的灰度值。灰度值的取值范围是[0,255],值越大,意味着这个点越白(亮)。
[ 计算机视觉的本质 ]
那么,一个彩色图,其实就是三个分别代表RBG的二维矩阵重叠构成。
这组二维矩阵的组成,则是我们计算机视觉的主要输入。我们通过各种方式处理这组二维矩阵,包括基础的图像处理,比如锐化,到一些高阶的机器学习方法,如提取图像的Gabor、Sift、LBP特征等。其实图像处理可以理解为二维输入的信号处理(很多领域都是交叉学科)。
我们通过这组二维矩阵,提取里面的信息完成我们想做的事情,这就是计算机视觉。
成就和问题
机器学习、深度学习的兴起,极大推动了计算机视觉、语音、语义(NLP)等领域的发展。目前我们使用人脸识别进行远程开户,使用微信语音转文字看“语音”,和Siri沟通。AI已经深入到我们生活的方方面面。
但机器学习也不是万能的。目前我们从实践来看,绝大部分AI只适用于特定领域,即还处于弱人工智能范畴,离强人工智能(通用人工智能)还有一段距离。不过此时的AI已经能做的确很多很多。
结语
AI作为已存在数十年的概念和行业,最近因算力和算法的突破又重获新生。本文简要陈述了AI的三次浪潮发展及对应的主流技术原理。感谢您的阅读。
腾讯云人脸识别(Face Recognition)基于腾讯优图世界领先的面部分析技术,提供包括人脸检测与分析、五官定位、人脸搜索、人脸比对、人脸验证、活体检测等多种功能,为开发者和企业提供高性能高可用的人脸识别服务。可应用于智慧零售、智慧社区、智慧楼宇、在线身份认证等多种应用场景,充分满足各行业客户的人脸属性识别及用户身份确认等需求。点击体验国内最佳人脸识别服务。欢迎留言讨论。
参考资料
[1]《人工智能狂潮——机器人会超越人类吗?》松尾丰
[2]《数学之美》吴军
[3]《人工智能》李开复